Menu
Disk Metrics – Why PerfMon’s, SQL Server’s Filestats, and Disk Vendors’ Values Sometimes Appear to Disagree
By Jeffry Schwartz | Expert
By Jeffry Schwartz | Expert
— By Jeffry Schwartz
Whenever multiple data sources are used, actual or perceived discrepancies can arise. Sometimes this is due to the location of the data collector, e.g., Windows, SQL Server, or the disk array. Other times, it is due to the collection rate and whether the information is a simple recording of continuously incremented data or it is an instantaneous sample. True sampling presents obvious issues because its accuracy is related directly to the sample rate. Clearly, the more often data is sampled, the more precisely it will represent actual behavior. However, this improved accuracy comes with the price of adding pressure to the disk, thereby distorting the picture of what the disk LUN is actually doing.
Disk Vendors
By default some disk array vendors sample disk performance data infrequently unless a more detailed view is required. This is important to know because this kind of sampling can miss spikes in activity completely, e.g., SQL Server checkpoints, which can be extremely write-intensive. As a result, a disk array that performs poorly during database checkpoints, but otherwise is effectively idle, will appear to be functioning well unless one of the samples happens to coincide with a checkpoint. Although the primary difference involves the sampling rate, the fact that the disk array measurements do not include the Windows I/O stack sometimes causes disk vendors to be suspicious of any Windows I/O metrics, and often suggest that either Windows’ I/O handling or its instrumentation is faulty. The author has not observed this.
Perfmon
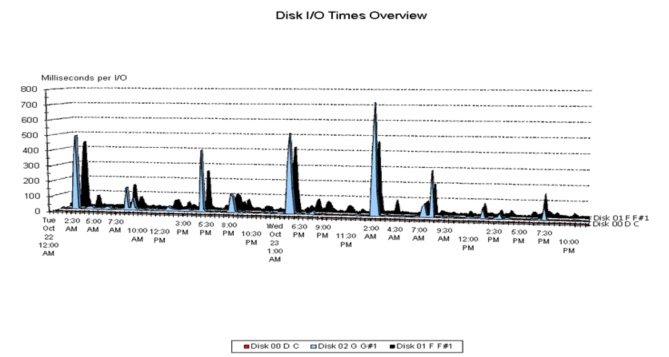
PerfMon and similar programs that rely upon Windows performance counters retrieve the averages for I/O metrics from the disk drivers themselves, i.e., from the code inside Windows that actually handles the I/Os. The “sampling” rate simply determines how often the averages are recorded (and reset for the next interval). Therefore, these are not true samples because the disk driver constantly updates its statistics and the collector periodically retrieves the averages. As a result, the disk driver will detect intermittent activities such as checkpoint behavior. The primary difficulty with these measurements is that any summarization of the data inevitably involves averaging averages. For example, assume that the collector retrieves the I/O data from the driver every 30 seconds and one needs to summarize disk behavior over a 15-minute period. In this scenario, the period average will be the average of 30 averages. The statistical literature is replete with examples of situations when this is sufficiently accurate, as well as those when it is not. Regardless, it is easy to understand why the averaging of averages is preferable to the alternative of highly frequent true sampling.
SQL Server FileStats

SQL Server captures I/O performance data differently. It records the times at which an I/O request is initiated and completed. It is important to note that in order to complete an I/O, the thread handling the I/O must pass through the processors’ ready queue and become active on a processor so the I/O completion code can be executed. If the processors are sufficiently busy, a delay will occur while the thread waits for a processor. Although SQL Server measures these kinds of delays for an entire instance, it does not expose them via the sys.dm_io_virtual_file_stats DMV. Therefore, differences between PerfMon’s and SQL Server’s measurements can be due to processor delays or the comprehensive nature of the SQL Server data, or the averaging of averages for PerfMon data. Unfortunately, there is no way to be certain without obtaining extremely detailed data, which, as cited previously, will distort any measurements. Note: if the SQL Server I/O metrics are captured and averaged every 30 to 60 seconds, the difficulties with averaging averages will be present in this data as well. Therefore, the only way to avoid this issue is to subtract the first snapshot’s values from those of the second and compute the differences. This method was used to compute the SQL Server metrics in the table below.
Differences
A simple example, whose data appears in the table below, helps illustrate the differences and similarities between PerfMon and SQL Server. The rightmost two columns illustrate the percentage and absolute differences for each pair of metrics. The Pct Diff SQL Server vs. PerfMon column highlights the percentage differences, whereas the last column lists the absolute differences. The read, write, and I/O times are in milliseconds, so clearly, the two disk LUNs shown below were under extreme duress during the data collection period, and reads and writes performed very poorly. Good read and write times should be 20 milliseconds or less, but the best time shown in the table below is 548 milliseconds. The similarities between the two data sources are notable because all of the rate values are close, although there is more variation in the response times, in particular for writes on LUN 10 O. Closer inspection reveals that LUN 09 N’s response metrics are very close and that the 10 O LUN accounts for most of the differences. However, despite the cited differences, both data sources support the conclusion that the disk LUNs performed very poorly.
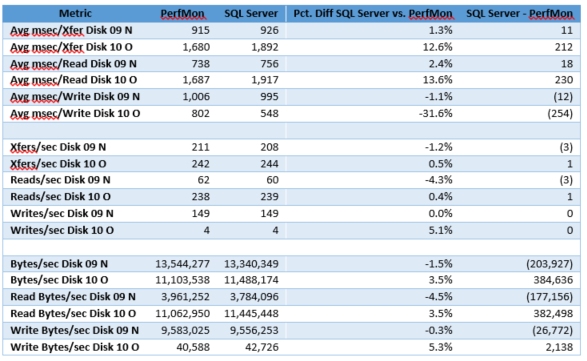
In summary, despite the significant differences in the origins of the PerfMon and SQL Server I/O metrics, both sets of metrics agree sufficiently and they also correctly detect I/O performance issues. Differences can result from the averaging of averages issues for PerfMon data, or processor-related delays and the comprehensive nature of the SQL Server I/O metrics. Regardless, either of these usually provides a more accurate representation of disk behavior than the infrequent sampling methods used by some disk vendors.
For more information about blog posts, concepts and definitions, further explanations, or questions you may have…please contact us at SQLRX@sqlrx.com. We will be happy to help! Leave a comment and feel free to track back to us. We love to talk tech with anyone in our SQL family!