Menu
Most analysts are familiar with missing index recommendations provided by SQL Server when query plans are displayed within SSMS or reported by various missing index DMVs. Several questions arise concerning these recommendations:
This article provides a reproducible example using six different queries that deliberately caused SQL Server to generate missing index recommendations and provide answers to these questions. The example is used to study missing index recommendations in detail, including how they relate to the underlying table and how query columns affect these recommendations. The article also illustrates how a single consolidated index can address the performance needs of all six queries.
To determine missing index recommendation behavior, a generic table was constructed and filled with 20 million records. Each record contained an identity column, an ID column, a text column, and 47 metric columns whose values ranged between 1 and 10,000,000. The large number of table columns was used to insure SQL Server would choose an index option when appropriate. Six queries that incorporated various column combinations were executed (some of which differed only in column ordering). To minimize duplication of column values and skewing of query plans, the ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000 formula was used to generate values that were as random as possible. Two indices were created: a clustered index that used the identity column as its only key and a second nonclustered index that used DupID as its only column. The scripts for the creation, loading, and initial indexing of the table are shown below.
— ##############################################################
— Create test table
— ##############################################################
drop table FewDuplicates;
CREATE TABLE FewDuplicates (
IDCol bigint identity (20000000,1),
DupID bigint,
MyText varchar(10),
Metric01 bigint, Metric02 bigint, Metric03 bigint, Metric04 bigint, Metric05 bigint,
Metric06 bigint, Metric07 bigint, Metric08 bigint, Metric09 bigint, Metric10 bigint,
Metric11 bigint, Metric12 bigint, Metric13 bigint, Metric14 bigint, Metric15 bigint,
Metric16 bigint, Metric17 bigint, Metric18 bigint, Metric19 bigint, Metric20 bigint,
Metric21 bigint, Metric22 bigint, Metric23 bigint, Metric24 bigint, Metric25 bigint,
Metric26 bigint, Metric27 bigint, Metric28 bigint, Metric29 bigint, Metric30 bigint,
Metric31 bigint, Metric32 bigint, Metric33 bigint, Metric34 bigint, Metric35 bigint,
Metric36 bigint, Metric37 bigint, Metric38 bigint, Metric39 bigint, Metric40 bigint,
Metric41 bigint, Metric42 bigint, Metric43 bigint, Metric44 bigint, Metric45 bigint,
Metric46 bigint, Metric47 bigint
)
— ##############################################################
— Load original table
— ##############################################################
declare @DupID bigint = 1
declare @NumRecs bigint = 20000000
truncate table FewDuplicates
set nocount on
while (@DupID <= @NumRecs)
begin
insert into [dbo].[FewDuplicates] (
[DupID], [MyText], [Metric01], [Metric02], [Metric03], [Metric04], [Metric05], [Metric06], [Metric07], [Metric08], [Metric09], [Metric10], [Metric11], [Metric12], [Metric13], [Metric14], [Metric15], [Metric16], [Metric17], [Metric18], [Metric19], [Metric20], [Metric21], [Metric22], [Metric23], [Metric24], [Metric25], [Metric26], [Metric27], [Metric28], [Metric29], [Metric30], [Metric31], [Metric32], [Metric33], [Metric34], [Metric35], [Metric36], [Metric37], [Metric38], [Metric39], [Metric40], [Metric41], [Metric42], [Metric43], [Metric44], [Metric45], [Metric46], [Metric47])
VALUES (
@DupID,‘my text’,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000,
ABS(cast(CHECKSUM(NewId()) as bigint)) % 10000000
)
set @DupID += 1
end — group option loop
set nocount off
— ##############################################################
— Create indices on the test table
— ##############################################################
CREATE UNIQUE CLUSTERED INDEX [ci_RecID] ON [dbo].[FewDuplicates]
(
[IDCol] ASC)
WITH (fillfactor = 100, PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
ON [PRIMARY]
CREATE NONCLUSTERED INDEX [ix_DupID] ON [dbo].[FewDuplicates]
(
DupID ASC
)
WITH (fillfactor = 100, PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
ON [PRIMARY]
The six queries all performed a range scan based upon DupID and Metric01. Clearly, the ix_DupID index could be used for the first portion of the where clause, but none of the existing indices could assist in the resolution of the second portion of the where clause. Note: All queries used identical where clauses to insure that the only query differences involved the columns that were requested in the select clause. These variations employed different combinations of the first six metric columns included a variety of column orderings. All of the queries returned the same 809 rows. Note: Due to the random nature of the data, the reader will not obtain identical results, but they will be functionally similar. Each query was run separately after the following commands had been executed:
dbcc dropcleanbuffers with no_infomsgs
dbcc freeproccache with no_infomsgs
dbcc freesystemcache(‘TokenAndPermUserStore’) with no_infomsgs
These commands clear all the pertinent caches to insure reproducibility and prevent memory-resident portions of the database from skewing the results. Each query required approximately 90 seconds to execute as shown in Table 1. Each query required approximately one million logical and physical reads to complete. The SSMS option for returning the actual execution plan was set prior to execution, and the six queries and execution plans are shown in the individual query sections below. The first five queries resulted in different recommendations, but the sixth query’s plan and recommended missing index were identical to that of the fifth because the only difference between Queries #5 and #6 is the ordering of the columns (part of the answer to question #2). The differences among all the queries are summarized in Table 2 below.
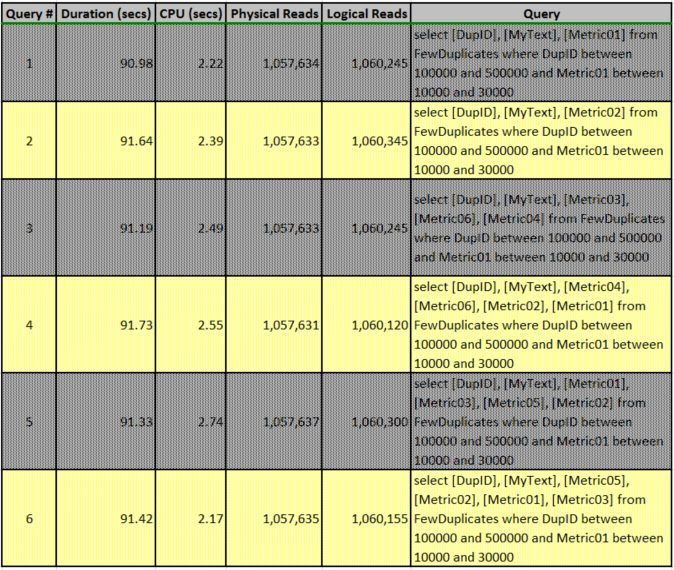
Table 1: Summary of Initial Query Executions & Timings
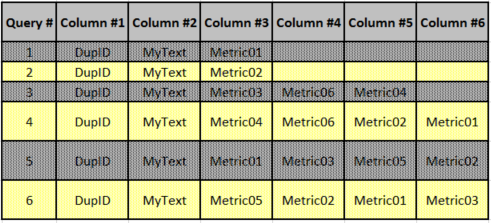
Table 2: Summary of Query Selection Columns
select [DupID], [MyText], [Metric01]
from FewDuplicates
where DupID between 100000 and 500000 and Metric01 between 10000 and 30000

select [DupID], [MyText], [Metric02]
from FewDuplicates
where DupID between 100000 and 500000 and Metric01 between 10000 and 30000

select [DupID], [MyText], [Metric03], [Metric06], [Metric04]
from FewDuplicates
where DupID between 100000 and 500000 and Metric01 between 10000 and 30000

select [DupID], [MyText], [Metric04], [Metric06], [Metric02], [Metric01]
from FewDuplicates
where DupID between 100000 and 500000 and Metric01 between 10000 and 30000

select [DupID], [MyText], [Metric01], [Metric03], [Metric05], [Metric02]
from FewDuplicates
where DupID between 100000 and 500000 and Metric01 between 10000 and 30000

select [DupID], [MyText], [Metric05], [Metric02], [Metric01], [Metric03]
from FewDuplicates
where DupID between 100000 and 500000 and Metric01 between 10000 and 30000

The following query was used to provide some of the information enumerated in Table 3 below:
— ##############################################################
— Missing Index DMV Query
— https://blogs.msdn.microsoft.com/bartd/2007/07/19/are-you-using-sqls-missing-index-dmvs/
— ##############################################################
SELECT migs.avg_total_user_cost * (migs.avg_user_impact / 100.0) * (migs.user_seeks + migs.user_scans) AS improvement_measure,
‘CREATE INDEX [missing_index_’ + CONVERT (varchar, mig.index_group_handle) + ‘_’ + CONVERT (varchar, mid.index_handle)
+ ‘_’ + LEFT (PARSENAME(mid.statement, 1), 32) + ‘]’
+ ‘ ON ‘ + mid.statement
+ ‘ (‘ + ISNULL (mid.equality_columns,”)
+ CASE WHEN mid.equality_columns IS NOT NULL AND mid.inequality_columns IS NOT NULL THEN ‘,’ ELSE ” END
+ ISNULL (mid.inequality_columns, ”)
+ ‘)’
+ ISNULL (‘ INCLUDE (‘ + mid.included_columns + ‘)’, ”) AS create_index_statement,
migs.*, mid.database_id, mid.[object_id]
FROM sys.dm_db_missing_index_groups mig
INNER JOIN sys.dm_db_missing_index_group_stats migs ON migs.group_handle = mig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details mid ON mig.index_handle = mid.index_handle
WHERE migs.avg_total_user_cost * (migs.avg_user_impact / 100.0) * (migs.user_seeks + migs.user_scans) > 10
ORDER BY migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) DESC
The following table lists the missing index recommendations as displayed by the DMVs. It also summarizes all of the missing index recommendations to make it easier to determine what a consolidated index might require. It is important to note that the missing index recommendations for Query #5 and #6 are the same, just as they were in the query plan listings above. Although discussion of the calculation and interpretation of the Improvement Measure column is beyond the scope of this article, it should be noted that the total improvement measure was approximately twice that of any other index recommendation and further investigation reveals that this index would satisfy both Query #5 and #6.
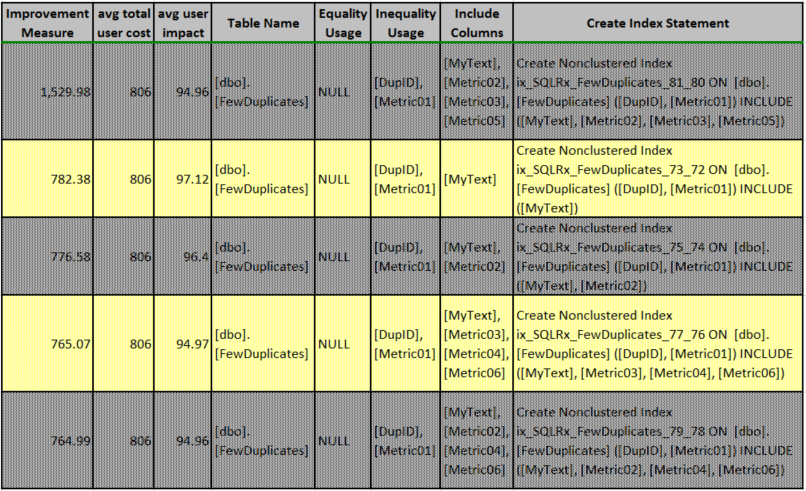
Table 3: Summary of All Missing Index Recommendations
Either Table 2 or Table 3 could be used to determine a composite index. In-depth investigation reveals that since DupID and Metric01 are specified in the where clauses as inequalities, these should be key columns in any index, and review of Table 3 highlights this for all index recommendations. Since MyText is used in all of the queries and Metric01 is to be used as a key column, the only remaining columns are Metric02, Metric03, Metric04, Metric05, and Metric06. An index that employs these columns as included columns can “cover” all the queries shown in this article. For further information about covering indices, please refer to the following article: https://docs.microsoft.com/en-us/sql/relational-databases/indexes/create-indexes-with-included-columns. The composite (and covering) index is shown below:
CREATE NONCLUSTERED INDEX ix_ResolveMultipleQueriesNeeds ON [dbo].[FewDuplicates] (
[DupID],
[Metric01]
)
INCLUDE (
[MyText],
[Metric02],
[Metric03],
[Metric04],
[Metric05],
[Metric06]
)
WITH (fillfactor = 100, PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
ON [PRIMARY]
Once the combined index was implemented, each query was run as before: caches cleared and SSMS actual execution plan option on. No query ran longer than one second even when the caches had been purged. Although the queries were run individually for the purposes of obtaining accurate timings, they were also run together for the purpose of showing the similarities of the execution plans with the new index in place. Table 4 lists the execution results and clearly, performance improved greatly for all queries. For example, durations decreased from approximately 90 seconds to about one second and reads dropped from approximately one million to four thousand. Examination of the query plans shows that all six queries used the new index to obtain the observed extremely fast performance.
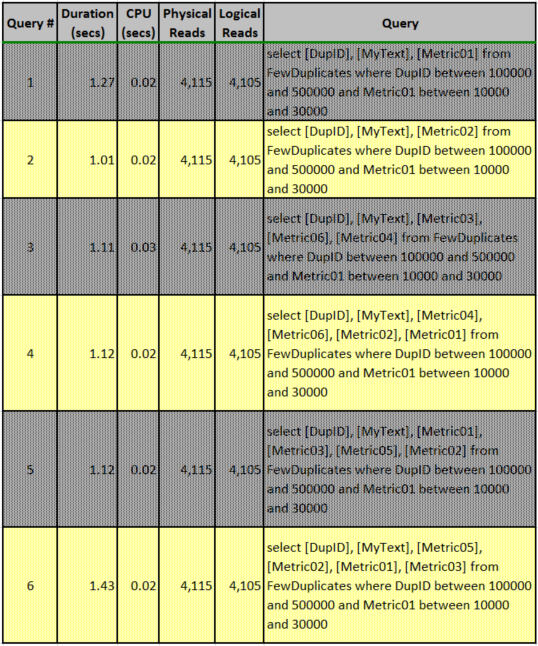
Table 4: Summary of Query Executions & Timings After Composite Index Added

Most readers probably already knew the answer to the first question: key columns are used to filter query results. The simplest example of this involves a where clause. Columns referenced by equalities are placed first, followed by columns that are used with inequalities. Some of the missing index DMVs actually differentiate between the types of relationships involved. The example queries show that table column ordering dictates included column order thereby answering question #2. Since table column ordering is used to specify included column ordering, SQL Server WILL NOT duplicate missing index recommendations when the columns are identical regardless of their ordering in the queries. The answer to the last question is that SQL Server does not appear to perform any consolidations or optimizations other than those cited in the answer to question #2. This knowledge is invaluable, particularly when evaluating missing index recommendations on production systems because unless the queries that cause SQL Server to generate the missing index recommendations have been executed recently, there is little information to associate the actual queries with the recommendations. Understanding those factors that affect SQL Server’s recommendations can simplify causing query identification and give an analyst more certainty that the correct associations have been made.
For more information about blog posts, concepts and definitions, further explanations, or questions you may have…please contact us at SQLRx@sqlrx.com. We will be happy to help! Leave a comment and feel free to track back to us. Visit us at www.sqlrx.com!